

JavaScript SEO – Common Issues with Dynamic Rendering

There is a connection between JavaScript and SEO that has developed throughout the years. Looking at websites that were created just a few years ago, it’s clear to see the impact of JavaScript SEO. Some developers did not have the knowledge that would allow them to determine whether search engines would be able to parse JavaScript content.

As the years have gone by, Google has tweaked its methodology and its view of JavaScript. This led some to doubt whether or not Google and other search engines were able to crawl JavaScript. In early 2018, Google announced that it would be offering official support for dynamic rendering for JavaScript-driven websites. There are two ways it can help. First, it would improve search on the server-side rendered SSR page. Second, it would provide increased UX for users.
In the SEO industry, we were glad about these developments. It was nice to see Google acknowledge the fact that JavaScript crawling capabilities of Google needed some improvement. It was also nice to see what a difference was between dynamic rendering and cloaking.
JavaScript-powered websites seem to be making a resurgence. While JS powered website is beginning to become more commonplace, especially for those seeking a visually-focused web experience, WordPress should still be the go-to choice for most new sites. If you are curious about how WordPress performs in comparison to JS-powered sites, take a peek at Hosting Canada’s WordPress report, detailing speed/performance over a 12 month period.
Before we dig more into JavaScript SEO specifics, it would be good to discuss how JavaScript works and how its implementation affects the search engine optimization process.
Understanding What JavaScript Is

JavaScript is an extremely popular programming language used in the development of websites. One can use a JavaScript framework to create the interactive aspects of web pages. It works as a controlling mechanism for the different elements on a page.
When it was first introduced, JavaScript’s framework was primarily on the client-side and only in browsers. With time, JavaScript code became embedded in the server-side of web servers and databases. From an SEO standpoint, this saves a lot of frustration. The challenge initially began when JavaScript implementation was dependent on client-side rendering.
Server-side rendering of JavaScript framework clears up any problems before they arise. Of course, to better understand the challenges of JavaScript SEO, you need to understand why certain problems appear, how to avoid these problems, and how search engines function.
Informational retrieval process works in three phases:
- Indexing
- Ranking
- Crawling
Ranking, Indexing, Crawling – The Holy Trinity of SEO
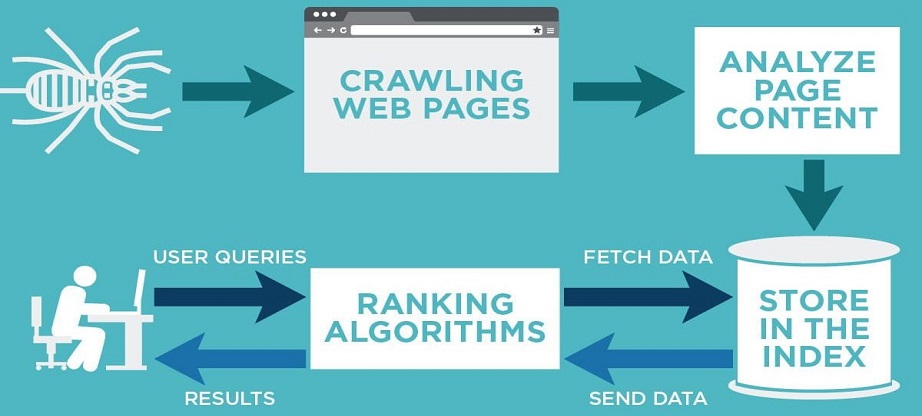
When discussing JavaScript SEO, you first start by looking at crawling and indexing. The ranking is something that comes later.
During the first phase of crawling, the focus is discovery. It is a complicated process that takes advantage of software programs known as spiders or web crawlers. The most popular crawler out there is Googlebot.
The first thing that a crawler is going to do is fetch a web page. From there, it is going to follow the trail of links on the page. Those pages are fetched, and then it will follow the links on those pages and repeat the process. This is how the pages are indexed. The crawler is not about rendering the pages. Its focus is on analyzing the source code. It is going to extract the URLs located in the script. Crawlers are able to validate hyperlinks as well as HTML code.
It’s important to remember that when you or someone looking for a product or service your website offers does a search on Google, they are not searching the web. They are searching Google’s index of the web. The index is what was created during that crawling process.
The next phase is the indexing. Indexing is where the URL is analyzed and the relevance of its content is determined. The indexer, likely Caffeine, attempts to render the pages as well as execute JavaScript using a WRS (web rendering service).
These two phases almost work in tandem. When the crawler finds something, it sends it to the indexer. The indexer, in turn, feeds more URLs to the crawler. At the same time, the indexer is giving priority to URLs based on their value.
When this process is complete and no errors are returned in the Search Console, the ranking process starts. This is where time and effort must be dedicated to quality content and website optimization happens. This way a viable link building takes place following the quality guidelines from Google.
Tip1 – Avoid Accidental Cloaking
As we mentioned, what the user sees when they look at your website and what a search bot sees are two different things. Your goal should be to minimize the difference between the two. You increase your risk if there are things implemented on the SSR that is only for Google. This means adding content on the page that users will not see for SEO purposes.
For example, you might add an additional keyword-targeted copy or remove aggressive ads. Avoid the trap of adding these features or text to the “SEO version.” As we discussed, dynamic rendering is not cloaking. However, using dynamic rendering as a way to create differences in content with the goal of influencing your ranking definitely is.
Differences of Googlebot and Caffeine in JavaScript SEO
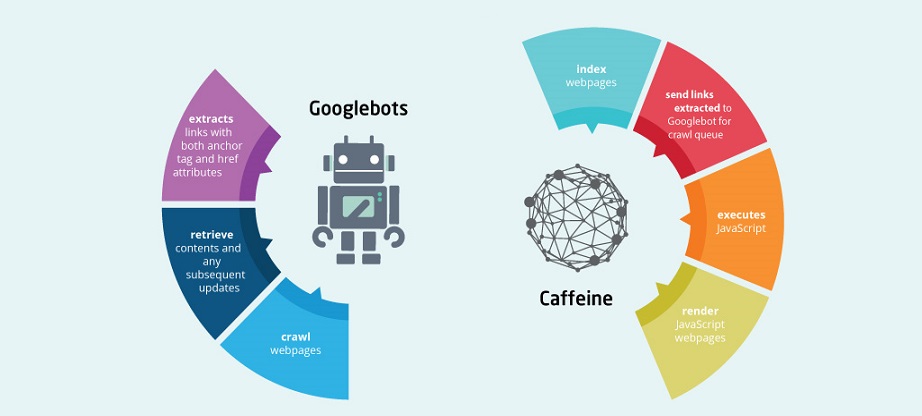
A number of problems start when people confuse Googlebot with Caffeine, which is part of the indexing process. It’s really easy to keep these two things separate. The crawler does not render content. The indexer does render content. The crawler’s job is to simply fetch the content. One reason why this concept gets muddled is that some people say that the crawler assists Google in indexing the content. That’s not altogether true.
You may hear a person ask if Googlebot can crawl and index JavaScript. Our answer is usually yes. Why do we say that? Because Google has the ability to render JavaScript and then rank pages based on the links it has extracted from it. Remember, Google includes a number of processes that allow information fetching and rendering.
It can be a touch overwhelming to fully grasp how the process of crawling and indexing is interconnected. This is why it can be easier to use JavaScript.
Tip 2 – Schedule Crawls for Monitoring SSR Issues
You may benefit from having to regular site crawl scheduled weekly or monthly based on your available resources. The purpose of the crawl is to identify issues. One should be as a Googlebot user agent. The other one should be a traditional JavaScript crawl. The latter of these two focuses on how your users are going to see the site. The Googlebot crawl is going to do a good job with monitoring dynamic rendering. It will identify issues that the average user browsing the site may not see. You want to search for signs that show a failed rendering. These might include a title, unexpected text, etc. In maybe good to review for duplicate content, content change percentage, and content similarity.
There are a number of monitoring sites that you may want to use to help you find the changes that you might not notice right away when you are at the site.
How Does JavaScript Affect SEO?
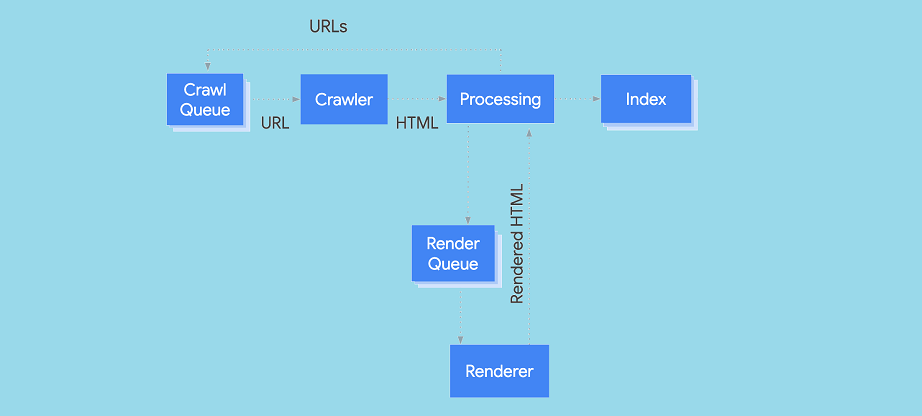
The benefits of JavaScript in search engine optimization and user experience are clear. Since code functions run instantly as opposed to waiting for the server to give an answer, they result in faster server load and more load time speed. JavaScript means higher versatility, easier implementation, and richer interfaces. An added bonus is that one can use JavaScript with a large number of applications. JavaScript SEO does present some challenges. Many webmasters do not optimize the content that uses JavaScript code.
The first question that you need to be able to clearly answer to understand JavaScript SEO is: Should I care that the indexer, not the crawler, takes care of JavaScript? The answer to that question is yes. It is important to care from an SEO standpoint. It’s also important to understand how this works in case there are errors. You want to know how to resolve whatever error is affecting your ranking.
Based on what we discussed, we understand that Google does not crawl JavaScript. We understand that Google does index JavaScript. So this helps us to see that there are circumstances where using JavaScript is going to be advantageous and other times when it is not.
Is a JavaScript website indexed and ranked? Absolutely. You can help Google along by using plug-ins that will make your JavaScript website search engine optimization friendly. When you take steps to make your content easier for Google to discover and easier for Google to evaluate, you’re going to have improved rankings.
Google is fully able to deal with JavaScript. True, JavaScript has some limitations and Google does have some challenges with it. However, the majority of these problems one can resolve if JavaScript is implemented correctly with JavaScript SEO in mind.
Tip 3 – Lookout for Design and CSS Failures in SSR
With dynamic rendering, a search bot will only see the SSR snapshot of the page. This version of the page is for visual analysis for mobile-friendly proximity, images, layout, etc. Be sure that you are glad about the page design as it appears for mobile, as this will be how it will be seen by the search user agent with Fetch Render. Your site may not render appropriately in the SSR because of a failed access to CSS resources or because the way CSS resources interact with JavaScript. Audit the page to make sure it looks the way that you want it to.
Making Your Page JavaScript SEO Friendly
If we hop in the Wayback machine to 2009, we remember that Google recommended using the Ajax crawling. In 2015 that proposal has no support. At the start, search engines couldn’t access content on Ajax-based websites and that was a challenge. It was impossible for the system to render and understand the page using JavaScript to generate dynamic content. This put the website and the site’s users at a disadvantage. With time, a number of guidelines make it easier for webmasters to index those pages.
In 2019, as long as you are not blocking Googlebot from crawling your CSS files or JavaScript, Google can generally understand and render your web page like modern browsers. It’s important that the content the Googlebot crawl sees is the same content the user sees. Having different content is cloaking, and we already discussed how that’s against Google’s quality guidelines.
The JavaScript code issues can be addressed if you use solutions such as:
- BromBone
- Angular JS SEO
- Prerender
When Google is indexing a web page, it’s looking at templates and not data. For this reason, it’s necessary to write code for the server that sends a version of that site to Google. A challenge faced with client rendered JavaScript links. It’s difficult to know if Google is able to follow the link and access the content. Google recommends using their Fetch as Google tool to let the Googlebot crawl JavaScript.
Final Words
With this article, we barely scratched the surface of JavaScript SEO. Clearly, JavaScript SEO is complex and has a lot of misunderstandings and gaps that need to be clarified in order to make things clear once and for all.
What is clear is that the retrieval process has three parts- crawling, indexing, and ranking. You are going to be able to improve your JavaScript SEO by having clear in mind how crawling and indexing works together as well as what separates the processes from each other. Googlebot is the crawler, and Caffeine is the indexer. Having these points clear in mind will erase a lot of the confusion that people have.
Something else that we have solidified is a fact that JavaScript’s website content can be indexed and ranked. It’s something that is done reluctantly, so you can improve the chances of your page being ranked by using plug-ins and tools that allow you to offer content and links in plain HTML. At the end of the day, it’s efficiency that’s important. You want to make the three processes, including index, crawl, and rank, as simple as possible for your web page.